content type paperpublished April 2024
Matryoshka Diffusion Models
AuthorsJiatao Gu, Shuangfei Zhai, Yizhe Zhang, Josh Susskind, Navdeep Jaitly
AuthorsJiatao Gu, Shuangfei Zhai, Yizhe Zhang, Josh Susskind, Navdeep Jaitly
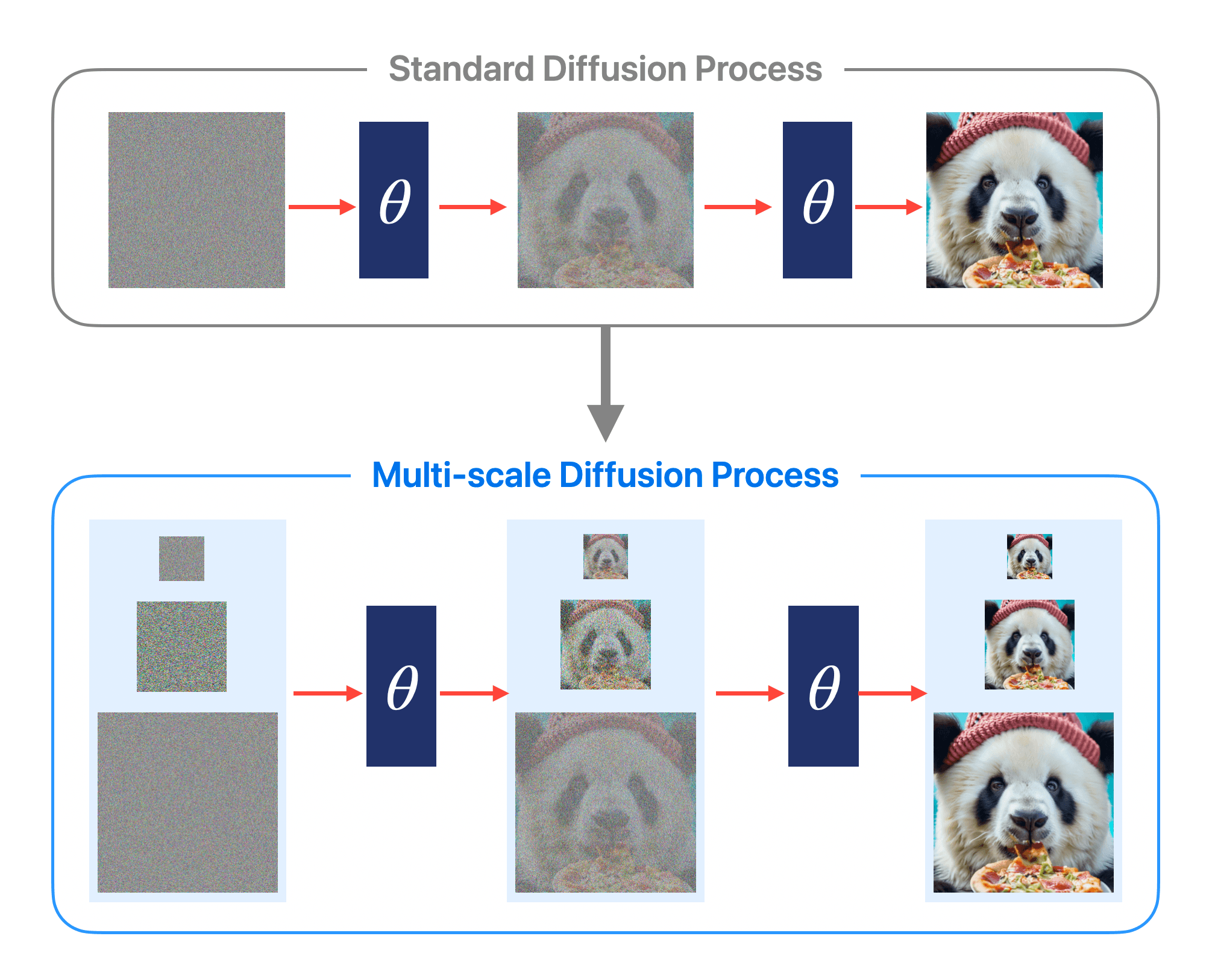
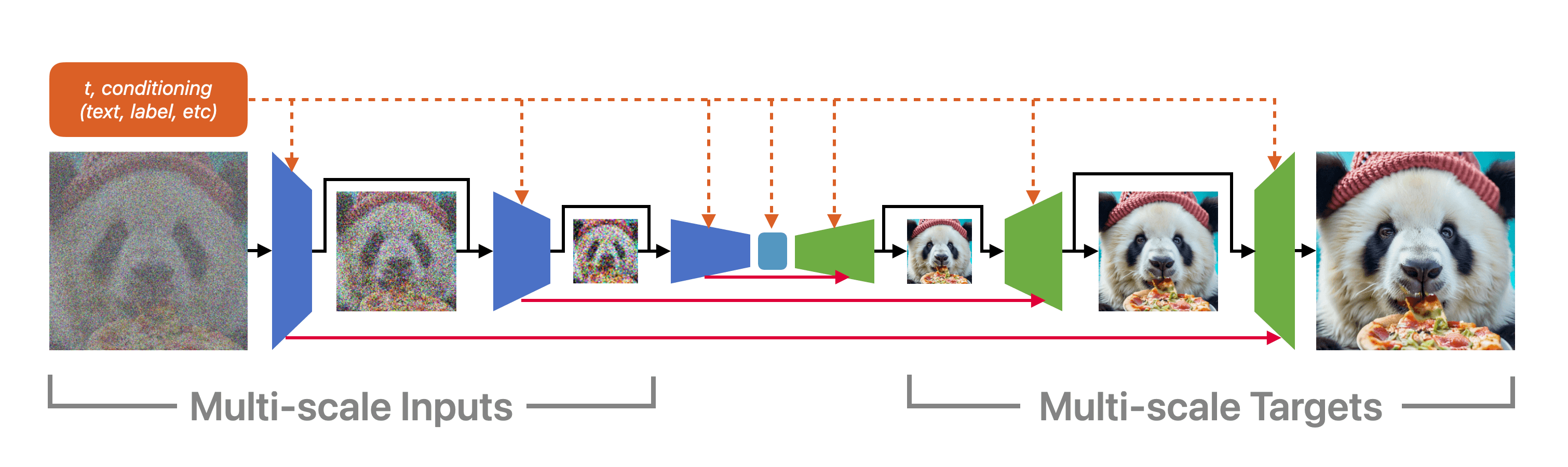
Diffusion models have demonstrated state-of-the-art performance in generating high-quality images and videos. However, due to computational and optimization challenges, learning diffusion models in high-dimensional spaces remains a formidable task. Existing methods often resort to training cascaded models, where a low-resolution model is linked with one or several upscaling modules. In this paper, we introduce Matryoshka Diffusion Models(MDM), an end-to-end framework for high-resolution image and video synthesis. Instead of training separate models, we propose a multi-scale joint diffusion process, where smaller-scale models are nested within larger scales. This nesting structure not only facilitates feature sharing across scales but also enables the progressive growth of the learned architecture, leading to significant improvements in optimization for high-resolution generation. We demonstrate the effectiveness of our approach on various benchmarks, including standard datasets like ImageNet, as well as high-resolution text-to-image and text-to-video applications. For instance, we achieve xx FID on ImageNet and xx FID on COCO. Notably, we can train a single pixel-space model at resolutions of up to 1024x1024 pixels with three nested scales.

April 16, 2025research area Speech and Natural Language Processingconference ICLR
July 17, 2024research area Computer Vision, research area Methods and AlgorithmsWorkshop at ICML

Our research in machine learning breaks new ground every day.