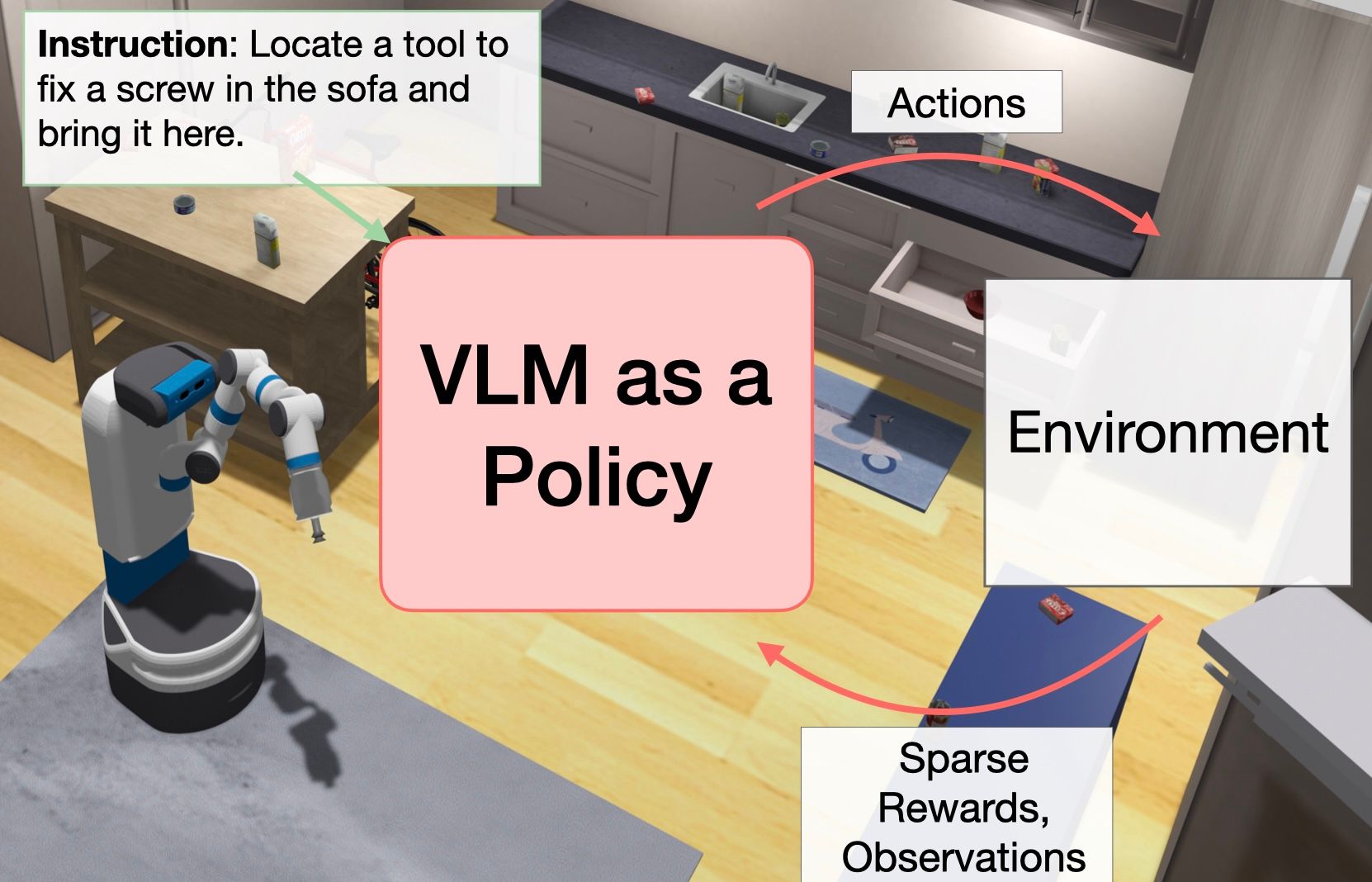
We show that large language models (LLMs) can be adapted to be generalizable policies for embodied visual tasks. Our approach, called Large LAnguage model Reinforcement Learning Policy (LLaRP), adapts a pre-trained frozen LLM to take as input text instructions and visual egocentric observations and output actions directly in the environment. Using reinforcement learning, we train LLaRP to see and act solely through environmental interactions. We show that LLaRP is robust to complex paraphrasings of task instructions and can generalize to new tasks that require novel optimal behavior. In particular, on 1,000 unseen tasks it achieves 42% success rate, 1.7x the success rate of other common learned baselines or zero-shot applications of LLMs. Finally, to aid the community in studying language conditioned, massively multi-task, embodied AI problems we release a novel benchmark, Language Rearrangement, consisting of 150,000 training and 1,000 testing tasks for language-conditioned rearrangement.
Figure 1: LLaRP: Adapting a Multimodal LLM as a Policy using online RL.
Progress in natural language processing enables more intuitive ways of interacting with technology. For example, many of Apple’s products and services, including Siri and search, use natural language understanding and generation to enable a fluent and seamless interface experience for users. Natural language is a rapidly moving area of machine learning research, and includes work on large-scale data curation across multiple languages, novel…
Reinforcement learning practitioners often avoid hierarchical policies, especially in image-based observation spaces. Typically, the single-task performance improvement over flat-policy counterparts does not justify the additional complexity associated with implementing a hierarchy. However, by introducing multiple decision-making levels, hierarchical policies can compose lower-level policies to more effectively generalize between tasks…