content type paperpublished July 2024
Careful With That Scalpel: Improving Gradient Surgery With an EMA
AuthorsYu-Guan Hsieh, James Thornton, Eugene Ndiaye, Michal Klein, Marco Cuturi Cameto, Pierre Ablin
AuthorsYu-Guan Hsieh, James Thornton, Eugene Ndiaye, Michal Klein, Marco Cuturi Cameto, Pierre Ablin
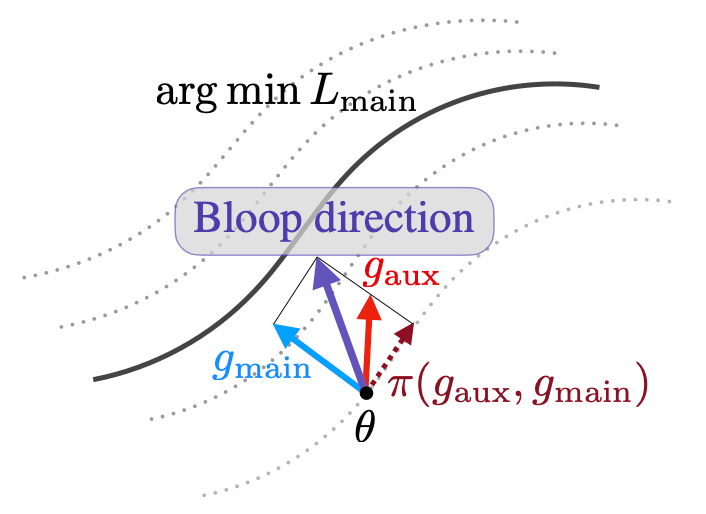
Beyond minimizing a single training loss, many deep learning estimation pipelines rely on an auxiliary objective to quantify and encourage desirable properties of the model (e.g. performance on another dataset, robustness, agreement with a prior). Although the simplest approach to incorporating an auxiliary loss is to sum it with the training loss as a regularizer, recent works have shown that one can improve performance by blending the gradients beyond a simple sum; this is known as gradient surgery. We cast the problem as a constrained minimization problem where the auxiliary objective is minimized among the set of minimizers of the training loss. To solve this bilevel problem, we follow a parameter update direction that combines the training loss gradient and the orthogonal projection of the auxiliary gradient to the training gradient. In a setting where gradients come from mini-batches, we explain how, using a moving average of the training loss gradients, we can carefully maintain this critical orthogonality property. We demonstrate that our method, Bloop, can lead to much better performances on NLP and vision experiments than other gradient surgery methods without EMA.
April 10, 2025research area Methods and Algorithmsconference ICLR
March 10, 2023research area Fairness, research area Methods and Algorithms

Our research in machine learning breaks new ground every day.